
Personal Software · AI

Robotic Arms for the Reading Mind
What is pdf gantry?
pdf-gantry is a command-line tool I wrote that enables me to interact with my research library in precise, composable, and expressive movements.
The mechanics are not exotic. It walks a folder of PDFs, hashes them, extracts the text and markdown, generates embeddings for each chunk, and stores everything in a single SQLite database. On top of that foundation sits a handful of composable commands: full-text search, semantic search, filename lookup, scoped context retrieval.
Everything has a --json flag so an agent can pipe one command into the next without parsing prose. gantry link reconciles the library against a BibTeX file by DOI, then filename, then fuzzy title, and assigns citekeys. Gantry reads my Obsidian vault but never writes to it. It can see my source notes and the citekey table in prime.bib, which lets it find papers by my own organizing terms rather than just by filename. The source notes are where my interpretive work accrues — quotes I’ve kept, wikilinks to adjacent ideas, etc.
I think of pdf-gantry as a robotic arm. Its job is ultimately to bring me things to read.
Most of the artificial intelligence on offer right now is built to be experienced as an oracle. You bring it a question and it hands back an answer. But there is an older tradition of personal computing, running through Douglas Engelbart1 and Alan Kay and the people at PARC, built on the premise that a computer should augment what a person does instead of answering for them.
An oracle produces a conclusion. An arm extends your reach.
It extends what you can do the way a warehouse arm extends what a worker can do. It can reach the box on the top shelf and the box at the back of the aisle, and it can do it without getting tired or losing focus. In this context of use, what distinguishes an arm from an oracle is where in the system the deciding happens. An arm does not know which box matters. You do. But nothing in the machine inherently enforces that division of labor. Worse, the system leans the other way. Producing conclusions is a language model’s resting state; fetching without concluding is the unnatural posture I hold it in. It will tell me which box matters not only the moment I ask, but in the absence of my asking, and it will sound just as certain when it is wrong.
The discipline of not asking is the only thing preserving the difference. It is counter-pressure against a tool that answers by reflex. And that discipline is mine to keep or to lose.
pdf-gantry has an industrial cousin. A warehouse arm reaches into a bin of jumbled goods, finds the one item that was ordered, and lifts it free,2 the same gesture I make when I reach into the heap for the paper I asked for. But the warehouse plan is bigger than the arm. The system decides what goes in the basket, in what order, and by whom; it sets the pace the worker has to match; and it is learning to do the picking itself. The arm begins as the worker’s tool and ends as the worker’s replacement. The analogy flatters my tool in one respect. Sparrow is mechanically incapable of pretending to know what it cannot; it can only grip and lift. My arm has no such innocence. It is an oracle I have asked to behave like an arm.
Knowledge work is on a similar trajectory. Companies now ask professionals to do the labor that trains their successors: labeling data, building RL environments, generating evaluations, strapping iPhones to their foreheads. So while I am excited about this cool tool that I made, I feel anxious about what it means that I built it.
When I introduce automation into my process, I become both the worker and the warehouse architect. I wrote the plan, the prompts, the order things get picked. I can practice the discipline of not asking the oracle only because I own the apparatus the arm is embedded in. I don’t think that is a virtue. It is a property of my position. I can privilege my preferences. I do not want it to read the papers for me. Because I curated these papers and built the intellectual context around them, I am the only one who knows what I am looking for—or what would pleasantly surprise me. What I want is a way to reach into the heap and pull out what I asked for, fast, in a form I can immediately use. I want the arm to be precise and intuitive. This is the system I want. I wish I was more convinced that I can keep the judgement on my side of the machine.
The serious context of use
On a dull afternoon pdf gantry helps me answer small questions. Find the maintenance section of my bike user manual3, or Which of my TTRPG source books had a class for an intrepid young reporter?4. Of course, that is not why I built it.
Andy Matuschak argues that the strongest tools for thought fall out of a serious context of use, as byproducts of a project you cared about for its own sake.5 Niche construction: a creature adapts to its world and also reshapes the world so the world comes to fit it, lowering its own future surprise by making its surroundings more predictable. Earthworms remake the soil they live in. People crossing a park wear a faint track into the grass, and the track invites the next walker, until there is a path no one drew. Geographers call those desire paths.
My library is a field of desire paths. Every paper I kept, every citekey, every source note where I left a quote and a wikilink to an adjacent idea, is a track worn by where my attention lingered. The last thing I want is an oracle-shaped system to pave a six-lane highway over that field, straight to a conclusion I never adequately considered.
These days I am working on an empirical study, and before I can code a single document I need a codebook — the set of rules that turns a passage of text into a piece of evidence. Codebooks are where most of the silent failures in qualitative research live. Build a weak one and you invalidate everything you do with it. Build a defensible one and you need to know what the working literature does. For my method6, that meant surveying 50+ empirical applications.
This is a task that calls for an arm. An oracular response would have read the 50 papers and told me which conventions to adopt: confident, opaque, plausibly wrong. If I am lucky, the system cites some grounding context I can independently review. The arm reads the 50 papers and tells me what each one did, with quoted evidence and a pointer back to the chunk. The interpretive call stays mine. The labor of reaching the top shelf does not.
To get a sense of scale, here is what I did with pdf-gantry over a few days last week:
- Library Discovery: A 5-agent OpenAlex sweep across author, citation, recommendation, keyword, and domain channels. Starting with 11 verified canonical papers as seeds, it returned 1,494 unique DNA-relevant papers. A “Tier-1” set of 89 papers was ranked by cross-validation strength (how many discovery channels independently surfaced each paper).
- Gap Identification: The arm cross-referenced Tier-1 against my local gantry library. 11 were already on my drive; 78 were in the “gap”—papers the field consensus says I should know about, but didn’t have.
- Acquisition and Ingestion: While I stepped away to actually read and think, a handful of background scripts downloaded the PDFs, ingested them, generated embeddings, and built the BibTeX entries. Ninety minutes of tedious bibliographic labor happened in the background while my attention was elsewhere.
- Focused Reading at Scale: Instead of asking an Oracle to summarize dozens of papers, I dispatched thematic batches of readers. Each was handed one paper, given my specific codebook, and told to extract quotes answering 2-4 open questions. I didn’t ask them for their opinion; I asked them to fetch evidence. The output was structured JSON per paper, containing cited quotes and a verdict per question (supports / refines / challenges / no_evidence) against my v0.1 default.
- Synthesis: A re-runnable Python script aggregated each batch’s per-paper outputs, tallied the verdicts, surfaced the strongest quotes, and rolled them into a master synthesis memo.
58 complete paper-reads yielded over 15 codebook revisions, each backed by named-paper evidence. This took about 20 hours of real elapsed time, but only 4 to 5 hours of my attention.
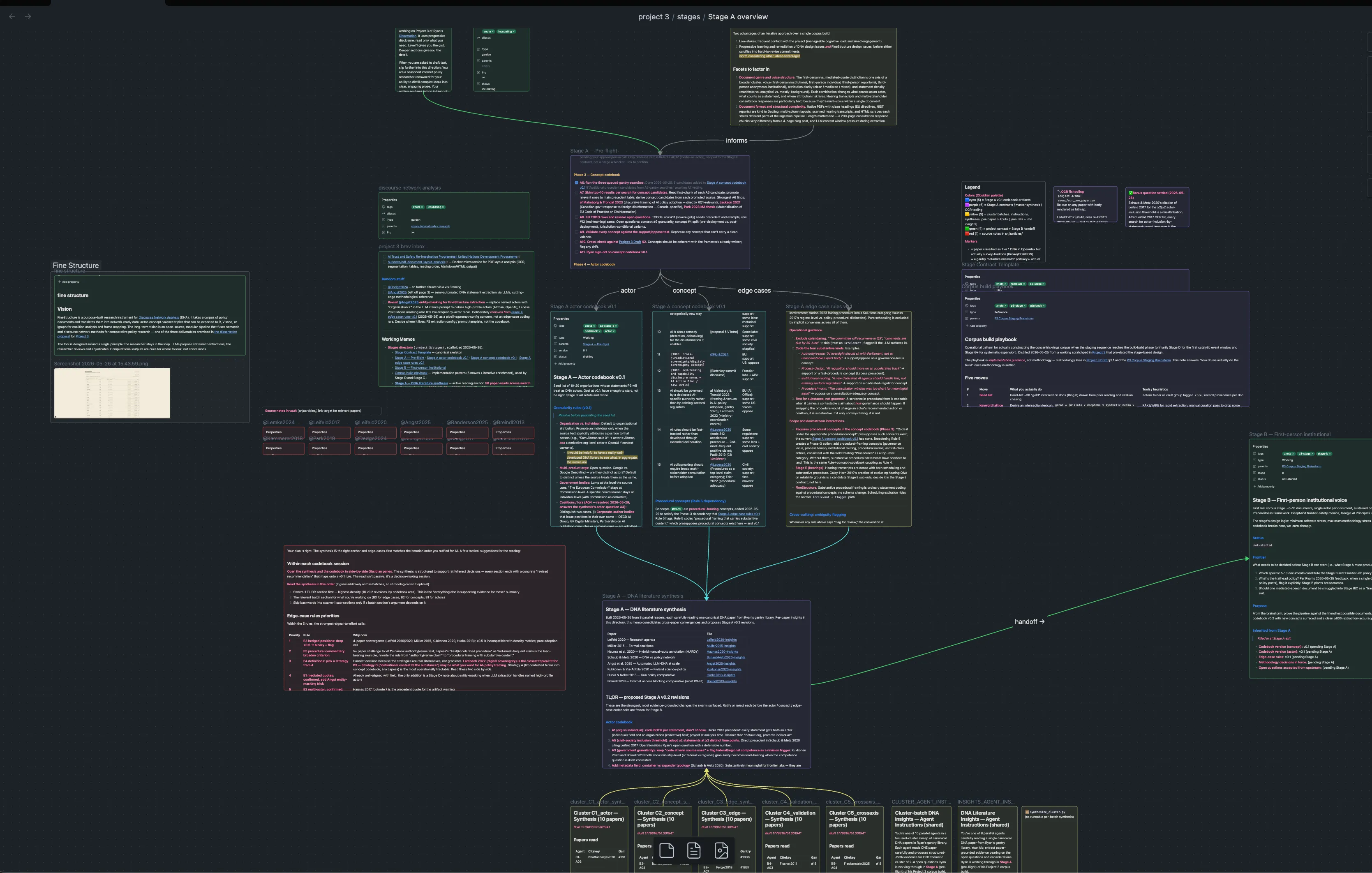
I chose which open questions were worth investigating. I designed the cluster structure. I curated which papers each batch should read based on my prior knowledge of the field. I wrote the prompts that turned a raw text-read into structured evidence. I read every synthesis output and made the final judgment calls on which revisions to adopt. In other words, I own the errors. The arm reported what it found; the bulk of the interpretive and curatorial work was mine.
This distinction is the difference between a claim and a map. An oracle says: “The field has settled on a standard threshold.” An arm says: “3 of these 10 papers use one threshold, 2 use another, 5 don’t address it, and here are the quotes.” The arm is at its best when it makes verification cheaper, not when it elides verification entirely.
Or this is the story I tell myself. The truth is more complicated. Look at step four. The agents did not only fetch evidence. They returned a verdict, and a verdict is a judgment. Deciding that a quote challenges a codebook rule means holding the rule, the paper’s claim, and the relation between them in mind at once. I have been talking about the difference between an arm and an oracle as if it is a state one reaches and holds. It is a ratio to be managed.
I caught silent failures because I deliberately had multiple agents read overlapping question clusters; redundancy surfaced the single-agent dropouts. I caught metadata errors because the arm makes it cheap to double-check the raw text. The way I use the gantry is relentlessly checkable. The combination of many cheap reads and audit-friendly outputs (cited quotes, database chunks, structured JSON) is what makes failures recoverable. Nothing prevents me from asking for an oracle-shaped response beyond my own practice. It is all too easy to adopt workflows that smuggle in oracular judgments. This is a tension I suspect we will all become familiar with in the coming years.
The Phenomenology of Trust
Here is an uncomfortable objection to all of this. The discipline of not asking the oracle is hardest to keep precisely when the arm is good.
A tool you have learned to trust eventually withdraws from your active attention; you stop reading it and start believing it, the way a skilled map-reader stops seeing the paper of the map and sees only the terrain. That is the moment the arm quietly becomes an oracle. Willpower is a poor defense here, because the whole problem is that trust erodes vigilance. The erosion is not only mine. A tool that answers fluently is, in effect, engineered to be believed; my vigilance is working against the grain of the thing. That is the deepest reason the defense has to live in the design rather than in my willpower — a single will is poorly matched against a system tuned to produce conviction.
Instead, I lean on the tool’s design. Cited quotes, database chunks, structured JSON, overlapping readers, a read I can simply redo with a keystroke when I notice a bad OCR scan: these keep the instrument conspicuous and demanding to be read. The discipline is not a moral failing or a triumph of the will; it is something I have to actively engineer into the workflow, so that checking the work stays cheaper than trusting the work, even after the trust has set in.
Compounding Organization
Even if this tooling froze today, I would get years of value out of it. But the models that puppet pdf-gantry are not standing still. We are watching two trajectories collide.
The first is Local Inference. Most of what the arm did last week does not require a massive frontier model. It requires a competent reader and a tightly defined task. The gap between what pdf gantry needs and what runs locally on a MacBook is closing fast. A free, always-available, modestly-capable local arm is a fundamentally different tool than a metered one, even if the metered one is technically smarter.
The second is Saved Routines. Last week’s sweep was not a one-off. Discover, ingest, cluster, read, synthesize—this is a sequence I will run again, with variations, on other literatures. The natural next step is to treat the sequence itself as a first-class object: a named, versioned, re-runnable routine. It is less like a script, which assumes identical inputs, and more like a musical score that I can re-perform on new material, with the human moves and the machine moves clearly marked.
In a powerhouse of an essay, Alondra Nelson recently reminded us that “technology is not an external force acting upon society from outside, but an internal phenomenon constituted through social processes.”7 The line between extending my reach and replacing my judgment is not a property of the model. It runs through what I build, what I measure, and what I refuse to ask. Nelson’s point cuts both ways here. If the line is socially constituted, then my ability to hold it is a fact about my situation and not my character. I keep the arm an arm because I own the warehouse it sits in and try to preserve my agency. For the worker inside someone else’s plan, the same discipline is not available. The niche is mine to construct, for now. Under current arrangements, the arm is a luxury good. It is available to those that own the context of use, foreclosed to employees, and trending the wrong way. I hope, as I iterate on pdf gantry, that I can continue groping toward meaningful augmentation instead of retreating to my own well-appointed warehouse.
Footnotes
-
Douglas Engelbart, “Augmenting Human Intellect: A Conceptual Framework” (1962). The whole research program aimed at raising what a person could do. ↩
-
This is Amazon’s Sparrow, a robotic arm that uses computer vision to recognize and pick individual products from bins of mixed inventory; Amazon says it can handle roughly two-thirds of the distinct items in its catalog. Amazon, “Amazon introduces Sparrow” (2022). ↩
-
this is where chunks become helpful. ↩
-
the answer is the wonderful ttrpg Realis, by Austin Walker. ↩
-
Andy Matuschak, “People who write extensively about note-writing rarely have a serious context of use” (notes.andymatuschak.org/z51q8prEJzs5Jqa5WPThYoV). His point is a byproduct principle: the most powerful tools for thought tend to emerge as side effects of pursuing a genuinely meaningful project, rather than from designing note-taking systems in the abstract. Luhmann is the type case, his Zettelkasten a byproduct of a research program he cared about for its own sake. pdf-gantry is that kind of byproduct. I built it to reach my own shelves while writing a dissertation, and the tool fell out of the work. ↩
-
The method is Discourse Network Analysis — it codes who says what alongside whom in policy debates, producing signed networks of actors and concepts. ↩
-
Alondra Nelson, “Field Theory: AI as Social Science Question, Object, and Tool,” Dædalus 155, no. 1–2 (Winter/Spring 2026), https://doi.org/10.1162/DAED.a.990. ↩


