
Research · AI

Toward Automated Discourse Network Analysis
1 · Structure, Boundaries, Change
When Sam Altman told a Senate subcommittee in May 2023 that “regulatory intervention by governments will be critical to mitigate the risks of increasingly powerful models,” he produced a codable claim: an identifiable actor took a discernible position on a nameable policy concept, on the record, at a moment in time. A researcher can write that down:
{
"actor": "Sam Altman",
"actor_org": "OpenAI",
"concept": "regulate_gen_ai",
"stance": +1,
"date": "2023-05-16"
}Once written down, it can be counted, compared, and connected.1
Discourse Network Analysis is a computational qualitative method built on this kind of record (Leifeld 2016b). Code every such statement in a policy debate as an actor–concept–stance triple, and the debate becomes a network: who agrees with whom, about what, and when. Coalitions surface as clusters of actors who keep taking the same positions; contested ideas surface as the fault lines between them; and because every statement carries a date, the dynamics of these structures become legible. The network form enables researchers to benefit from a mature analytic toolkit. A single collection of coded statements project into actor-agreement, actor-conflict, and concept co-occurrence networks, and clustering and centrality measures interrogate each projection differently.
Consider the case of my dissertation: how expert policy communities are making sense of generative AI’s deceptive capabilities. In 2019, Singapore’s POFMA and Canada’s Directive on Automated Decision-Making treated disinformation and artificial intelligence as separate policy problems. One law aimed at human-written propaganda, the other at algorithms making back-office decisions. Within five years, that separation had collapsed: Singapore criminalized AI-generated deepfakes in its election law, and Ottawa redefined AI itself as a producer of text, images, audio, and video “capable of fueling misinformation.”2 These paired revisions are visible traces of something larger. Two expert policy communities — AI governance and information-disorder governance — are renegotiating their boundary in public, statement by statement, across thousands of documents. How that contest settles will fix what kind of problem AI-enabled deception is understood to be — what it gets named, whose expertise counts, which storylines organize official attention — and, downstream of those settlements, which governance instruments look reasonable, urgent, or unthinkable.3 The collision is unfolding in a corpus far larger than any discourse network study has ever hand-coded, which is why the method best suited to the question has never been applied to anything like it.
In what follows, I trace that bottleneck to its root in the price of expert judgment, introduce a high-level design for automating the method that keeps the researcher in command of meaning, and preview the open-source workbench I am building for human-machine teaming on discourse networks.
2 · Qualitative Insight at Internet Scale
Every edge in a discourse network begins as a human judgment. A trained coder reads every document, isolates each codable statement, resolves who is speaking, matches the claim against a concept codebook, and assigns a stance. Interpretive judgments are applied sentence by sentence, thousands of times over. The published record shows the ceiling this imposes. Sosa Popovic and Welfens (2025), a strong recent exemplar, built their discourse network study of EU refugee framing from 175 news articles, 870 coded statements, and 84 actors: months of skilled labor, and still hundreds of documents rather than thousands.
That ceiling shapes what gets studied. DNA’s analytical payoff is established across dozens of policy domains, from pension reform to climate politics, but study designs shrink to fit coding budgets, and corpus-scale questions — the kind the boundary collision above poses — go unasked. Leifeld named the missing piece himself in the method’s canonical overview: “semiautomatic statement recognition,” he wrote, “is an active research frontier that has the potential to save a tremendous amount of manual coding efforts and at the same time potentially increase the reliability of the coding” (Leifeld 2017). That call has stood open for nearly a decade.
3 · Decomposing Qualitative Analysis into Natural Language Operations
Fortunately, DNA can be conceptualized as a set of natural-language operations: recognizing named actors, detecting an actor’s stance toward a proposition, matching a claim against a controlled vocabulary. In isolation, none of these operations requires especially sophisticated reasoning. It is the composite that becomes expensive — hundreds of such decisions, made in sequence by a single expert at human reading speed. Leifeld anticipated the solution in 2017, sketching “a supervised, multistep prediction procedure based on named entity recognition” as the most promising direction for statement recognition. That is, nearly term for term, the affordance language models now supply off the shelf.
Entity recognition, stance detection, and semantic matching have each reached research-grade performance in published evaluations — including on open-weight models small enough to run locally (Angst et al. 2025; Gao and Feng 2025). A study can cross-validate and freeze its instrument as a citable artifact, without depending on a vendor’s capricious access decisions.4 The determinative development is economic: the price of running models at a fixed measured capability has collapsed. Epoch AI’s analysis of inference-price trends finds declines of 9× to 900× per year depending on the task; performance that cost roughly thirty dollars per million tokens in early 2023 is available today for under one, and batch processing halves that again.5 Dedicated software can compound these gains with judicious use of context caching and related techniques. First-pass coding of several thousand policy documents — work that would consume a funded coding team for years — now costs less than the conference travel to present it. The binding constraint on corpus-scale discourse analysis has moved from the cost of coding to the design of validation.
The pipeline treats the model as a measurement instrument whose error structure must be characterized instead of a coder whose judgment is trusted. “We used GPT to code our data” is a phrase that names the practice skeptics rightly distrust and the caricature by which they dismiss the enterprise entirely. Taking models seriously as research instrumentation means naming the failure modes and measuring them: where a model drifts, which categories drive its errors, what biases its training or prompts introduce. The researcher builds the workflow around those measurements.
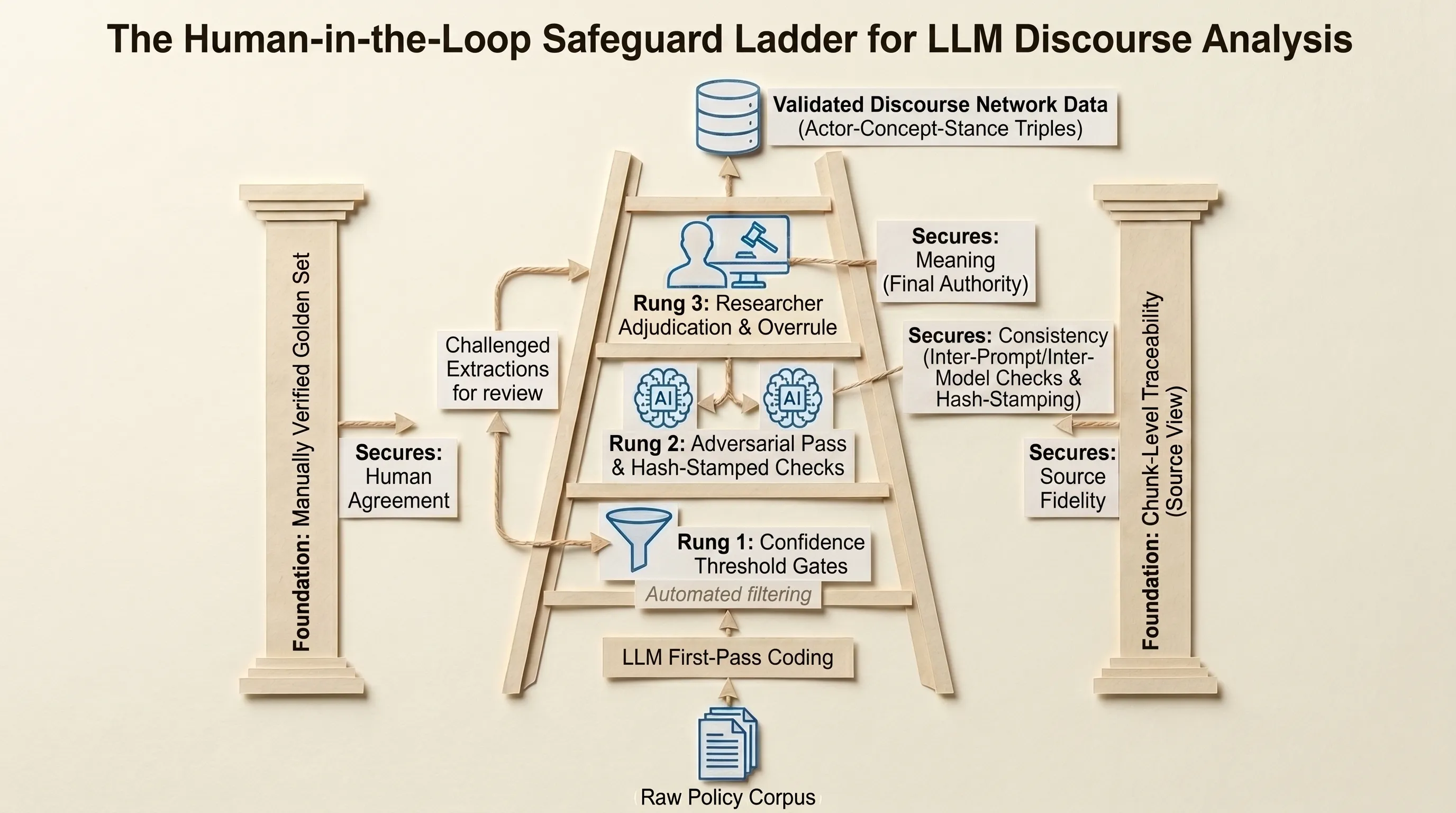
The design places first-pass coding under what I call a human-in-the-loop safeguard ladder. Confidence thresholds gate which extractions surface for review; an adversarial second-model pass challenges low-agreement extractions; and final authority rests with the researcher, who can overrule any extraction that conflicts with the codebook’s definitions. Beneath those rungs sit two further commitments: a manually verified Golden Set of coded statements against which every prompt revision is evaluated, and chunk-level traceability, so every coded statement maps back to the exact source passage that produced it. The researcher remains the adjudicator throughout. Scale itself supplies a complementary check. Angst and colleagues show that stance classifications with a per-statement F1 of only 0.60 recover gold-standard network structure (F1 ≈ 0.9) once aggregated over multi-year windows.
Taking the obvious objection seriously — is the model coding correctly? — is itself a productive design exercise, because the literature’s stock answer conceals an ambiguity. “Validate against a hand-coded sample” sounds like one prescription, but across the LLM-annotation literature it names at least four distinct referents, each licensing a different claim (Table 1).
| Validation referent | Exemplars | The claim it licenses | What it leaves open |
|---|---|---|---|
| Human agreement | Pangakis et al. 2023; Than et al. 2025 | The model coded as your humans would have | Whether the humans were right — Gartlehner et al. (2024) found 21 errors in their own gold standard |
| Team coverage | Chen et al. 2024 | The model missed less of what a coding team collectively saw | Correctness |
| Run-to-run consistency | Tai et al. 2024 | The model answers the same way tomorrow | Quality |
| Source fidelity | Bartalesi et al. 2024 | The output preserved its input text | Meaning |
The Golden Set targets human agreement; inter-prompt and inter-model checks target consistency; chunk traceability targets source fidelity; and the adjudicating researcher carries the residual burden no metric covers, which is meaning. No single number certifies “validity,” and a design that pretends otherwise has left a rung untested.6
4 · FineStructure
The scheme above is only workable to the extent it is operationalized in deterministic software. FineStructure is that software: an open-source pipeline purpose-built for corpus-scale discourse network analysis, built on research infrastructure I first developed for the Global Disinformation Policy Database. I am leveraging my years of constructing billion-edge networks from web data in order to build a development environment for network representations of social phenomena. The system’s chunk viewer renders every coded statement beside the exact passage the model saw, bringing source fidelity into the interface. An actor-resolution workspace and a keyboard-driven triage queue make adjudication fast enough that the researcher stays in the loop at corpus scale. Every extraction is stamped with a hash of its prompt and codebook configuration, so consistency checks compare like with like. The export pipeline emits node and edge files, keeping downstream analysis auditable from raw document to published network. Other researchers can interrogate the corpus, re-run the pipeline, and dispute the coding statement by statement.
At present, I am testing the software against a corpus developed for my dissertation work. I take inspiration from mature editing environments like Gephi, VScode, and Obsidian. You work in those tools rather than run them — and at large enough scale, keeping a researcher in command of meaning takes an environment, not a script.
5 · New Ways of Seeing
Nothing in this design is specific to AI and disinformation. AI and biosecurity, fintech and consumer protection: wherever a disruptive technology forces two policy communities into contact, the same boundary-spanning measurement problem appears. Studying a new collision means writing two new codebooks: the actors participating in the conversation and the claims that structure the discursive space. The method, the software, and the validation logic can be reused and are thus subject to compounding improvements as model capabilities evolve and researchers learn lessons about large scale DNA.
The larger promise is a new way of seeing collective sense-making. The theory underlying this work holds that frames are collective accomplishments: no ministry, platform, or NGO owns the meaning of issues like AI-enabled deception, which forms instead from patterned statements and rebuttals among many actors over time. That claim has long outrun our ability to observe it and the corpus scale brings it into view. Questions the policy sciences usually settle by assumption come within reach: whether a “policy community” is a real, bounded thing or an analyst’s convenience can now be read from the clustering, persistence, and dissolution of its agreement ties, rather than stipulated in advance.
In the context of frontier AI, each capability shock becomes a natural experiment in how interpretive communities absorb disruption. Policy organizations are now adopting LLM-assisted analysis pipelines of their own, and every one of them faces the question this design is built around: validate against what? A validation scheme that names which referent each check secures is, in effect, an assurance case for machine-assisted research. By recasting familiar qualitative methods into atomic natural language operations, this work scales a study to the phenomenon rather than the coding budget.
Footnotes
-
Testimony before the U.S. Senate Judiciary Subcommittee on Privacy, Technology, and the Law, May 16, 2023. The encoding is a simplified form of the statement schema used in the pipeline described below. Labels like
regulate_gen_aiare pointers into a concept codebook: the full entry articulates a directional claim specific enough for an actor to support or oppose, with inclusion rules and worked examples. ↩ -
Singapore: Protection from Online Falsehoods and Manipulation Act (2019); Elections (Integrity of Online Advertising) (Amendment) Act (2024). Canada: Directive on Automated Decision-Making (2019); Guide on the Use of Generative AI (2023). ↩
-
On framing as ongoing meaning-making work — naming, selecting, storytelling — see van Hulst (2016); on problem definition steering agendas and venue assignment, Baumgartner and Jones (1993). ↩
-
The concern is not hypothetical. Commercial providers retire models on their own schedules — OpenAI gave three days’ notice before discontinuing its Codex API in March 2023, and has since sunset the dated model snapshots (e.g.,
gpt-4-0314,gpt-3.5-turbo-0301) that researchers pin precisely to fix a version for replication. Closed models can also shift behavior under an unchanged name: Chen, Zaharia, and Zou (2024) document GPT-4’s accuracy on one task falling from 84% to 51% between two 2023 releases of the same service. Chen, L., M. Zaharia, and J. Zou (2024), “How Is ChatGPT’s Behavior Changing over Time?”, Harvard Data Science Review 6(2); model retirement schedules at OpenAI, “Deprecations,” platform.openai.com/docs/deprecations. ↩ -
Cottier, B., B. Snodin, D. Owen, and T. Adamczewski (2025), “LLM inference prices have fallen rapidly but unequally across tasks,” Epoch AI, epoch.ai/data-insights/llm-inference-price-trends. The estimate is conservative about frontier capability: it tracks price at fixed measured performance on public benchmarks. ↩
-
The four-referent analysis derives from a living bibliography of the LLM-assisted coding literature that I curate (19 entries as of this writing; activationlayer.org/bibliography). ↩


